Munin’s Architecture¶
Components¶
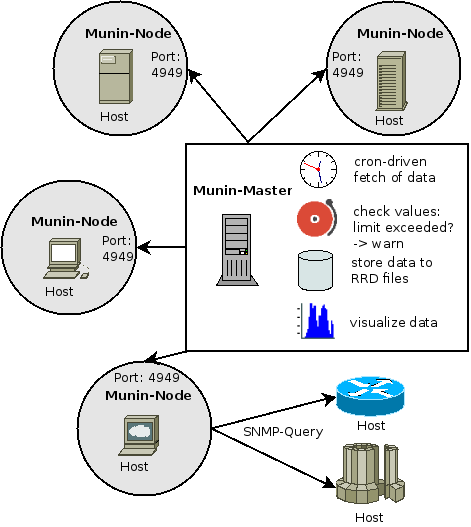
Here we describe the components of Munin. On page Protocols we talk about the rules for interaction between them.
Munin-Master¶
The master is responsible for all central Munin-related tasks.
It regularly connects to the various nodes, and then synchronously asks for the various metrics configuration and values and stores the data in RRD files.
On the fly the values are checked against limits (that you may set) and the Munin-Master will croak, if values go above or below the given thresholds.
Here we also generate the graphs, as this is a heavy task that needs some resources. Recent versions of Munin use cgi-graphing to generate graphs only when the user wants to see them.
Munin-Node¶
The node is a small agent running on each monitored host. We can have agent-less monitoring but this is a special case that will be addressed later. On machines without native support for Perl scripting you can use munin-c, which is a C rewrite of munin node components. (Look for the details in the munin-c chapter.)
Note that a usual setup involves having a node running also on the master host, in order for munin to monitor itself.
Munin-Plugin¶
The munin plugin is a simple executable, which role is to gather one set of facts about the local server (or fetching data from a remote machine via SNMP)
The plugin is called with the argument “config” to get metadata, and with no arguments to get the values. These are mandatory arguments for each plugin. We have some more standard arguments, which play a role in the process of automatic configuration.
Relations¶
- Each Munin master may monitor one or more Munin nodes (1:n)
- More than one Munin master may monitor one or more Munin nodes (n:m)
- Does this confuse lightly stupid plugins?
- Is “multi-master” configurations tested, known and/or documented?
- Does the Plugin-writing-howto describe how the plugin should behave if queried more often than in five minutes intervals and/or from different Munin masters?
- Each Munin node controls one or more plugins (1:n)
- Each plugin returns, when queried:
- One or more general directives to control the plugin itself, with corresponding values
- One or more data sources (fields) described by fieldname (1:n)
- Each data source has one or more attributes (1:n), with corresponding values